
I am still reading Shadow of Oz by Dr. Wayne Rossiter, and I definitely plan to post a review of it when I am finished. However, I wanted to write a separate blog post about one point that he makes in Chapter 6, which is entitled “Biological Evolution.” He says:
To date, the National Center for Biotechnology Information (NCBI), which houses all published DNA sequences (as well as RNA and protein sequences), currently acknowledges nineteen different coding languages for DNA…
He then references this page from the NCBI website.
This was a shock to me. As an impressionable young student at the University of Rochester, I was taught quite definitively that there is only one code for DNA, and it is universal*. This, of course, is often cited as evidence for evolution. Consider, for example, this statement from The Biology Encyclopedia:
For almost all organisms tested, including humans, flies, yeast, and bacteria, the same codons are used to code for the same amino acids. Therefore, the genetic code is said to be universal. The universality of the genetic code strongly implies a common evolutionary origin to all organisms, even those in which the small differences have evolved. These include a few bacteria and protozoa that have a few variations, usually involving stop codons.
Dr. Rossiter points out that this isn’t anywhere close to correct, and it presents serious problems for the idea that all life descended from a single, common ancestor.
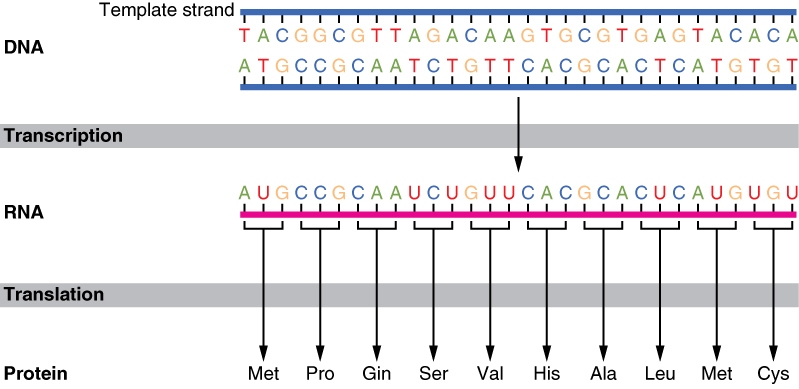
To understand the importance of Dr. Rossiter’s point, you need to know how a cell makes proteins. The basic steps of the process are illustrated in the image at the top of this post. The “recipe” for each protein is stored in DNA, and it is coded by four different nucleotide bases (abbreviated A, T, G, and C). That “recipe” is copied to a different molecule, RNA, in a process called transcription. During that process, the nucleotide base “U” is used instead of “T,” so the copy has A, U, G, and C as its four nucleotide bases. The copy then goes to the place where the proteins are actually made, which is called the ribosome. The ribosome reads the recipe in units called codons. Each codon, which consists of three nucleotide bases, specifies a particular amino acid. When the amino acids are strung together in the order given by the codons, the proper protein is made.
The genetic code tells the cell which codon specifies which amino acid. Look, for example, at the illustration at the top of the page. The first codon in the RNA “recipe” is AUG. According to the supposedly universal genetic code, those three nucleotide bases in that order are supposed to code for one specific amino acid:methionine (abbreviated as “Met” in the illustration). The next codon (CCG) is supposed to code for the amino acid proline (abbreviated as Pro). Each possible three-letter sequence (each possible codon) codes for a specific amino acid, and the collection of all those possible codons and what they code for is often called the genetic code.
{kind=link}
Now, once again, according to The Biology Encyclopedia (and many, many other sources), the genetic code is nearly universal. Aside from a few minor exceptions, all organisms use the same genetic code, and that points strongly to the idea that all organisms evolved from a common ancestor. However, according to the NCBI, that isn’t even close to correct. There are all sorts of exceptions to this “universal” genetic code, and I would think that some of them result in serious problems for the hypothesis of evolution.
Consider, for example, the vertebrate mitochondrial code and the invertebrate mitochondrial code. In case you didn’t know, many cells actually have two sources of DNA. The main source of DNA is in the cell’s nucleus, so it is called nuclear DNA. However, the kinds of cells that make up vertebrates (animals with backbones) and invertebrates (animals without backbones) also have DNA in their mitochondria, small structures that are responsible for making most of the energy the cell uses to survive. The DNA found in mitochondria is called mitochondrial DNA.
Now, according to the hypothesis of evolution, the kinds of cells that make up vertebrates and invertebrates (called eukaryotic cells) were not the first to evolve. Instead, the kinds of cells found in bacteria (called prokaryotic cells) supposedly evolved first. Then, at a later time, one prokaryotic cell supposedly engulfed another, but the engulfed cell managed to survive. Over generations, these two cells somehow managed to start working together, and the engulfed cell became the mitochondrion for the cell that engulfed it. This is the hypothesis of endosymbiosis, and despite its many, many problems, it is the standard tale of how prokaryotic cells became eukaryotic cells.
However, if the mitochondria in invertebrates use a different genetic code from the mitochondria in vertebrates, and both of those codes are different from the “universal” genetic code, what does that tell us? It means that the eukaryotic cells that eventually evolved into invertebrates must have formed when a cell that used the “universal” code engulfed a cell that used a different code. However, the eukaryotic cells that eventually evolved into vertebrates must have formed when a cell that used the “universal” code engulfed a cell that used yet another different code. As a result, invertebrates must have evolved from one line of eukaryotic cells, while vertebrates must have evolved from a completely separate line of eukaryotic cells. But this isn’t possible, since evolution depends on vertebrates evolving from invertebrates.
Now, of course, this serious problem can be solved by assuming that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work. Along with explaining how nuclear DNA can evolve to produce the new structures needed to change invertebrates into vertebrates, evolutionists must also explain how, at the same time, mitochondria can evolve to use a different genetic code!
In the end, it seems to me that this wide variation in the genetic code deals a serious blow to the entire hypothesis of common ancestry, at least the way it is currently constructed. Perhaps that’s why I hadn’t heard about it until reading Dr. Rossiter’s excellent book.
*Addition (4/3/2017): After speaking with a biology professor for whom I have a lot of respect, I need to make an addendum. She says that nowadays, the term “universal genetic code” doesn’t necessarily mean that every organism uses the same set of codons for the same amino acids. One could say that the genetic code is universal in the sense that all organisms use three nucleotide bases to define an amino acid, the codes can all be translated at the ribosome, etc. I still think that these alternate genetic codes argue against evolution, but it is important to note that some evolutionists use the term “universal” without implying that the codons are all the same among all organisms.
Return to Text
I agree, it is an excellent book–a must-read, in my opinion. Chapter 6 is perhaps the most challenging, but also one of the most rewarding chapters in the book.
Venter vs. Dawkins on the Tree of Life – and Another Dawkins Whopper – March 2011
Excerpt:,,, But first, let’s look at the reason Dawkins gives for why the code must be universal:
“The reason is interesting. Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster.” (2009, p. 409-10)
OK. Keep Dawkins’ claim of universality in mind, along with his argument for why the code must be universal, and then go here (linked site listing 19 variants of the genetic code).
Simple counting question: does “one or two” equal 19? That’s the number of known variant genetic codes compiled by the National Center for Biotechnology Information. By any measure, Dawkins is off by an order of magnitude, times a factor of two.
http://www.evolutionnews.org/2011/03/venter_vs_dawkins_on_the_tree_044681.html
Multiple Overlapping Genetic Codes Profoundly Reduce the Probability of Beneficial Mutation George Montañez 1, Robert J. Marks II 2, Jorge Fernandez 3 and John C. Sanford 4 – published online May 2013
Excerpt: In the last decade, we have discovered still another aspect of the multi-dimensional genome. We now know that DNA sequences are typically “ poly-functional” [38]. Trifanov previously had described at least 12 genetic codes that any given nucleotide can contribute to [39,40], and showed that a given base-pair can contribute to multiple overlapping codes simultaneously. The first evidence of overlapping protein-coding sequences in viruses caused quite a stir, but since then it has become recognized as typical. According to Kapronov et al., “it is not unusual that a single base-pair can be part of an intricate network of multiple isoforms of overlapping sense and antisense transcripts, the majority of which are unannotated” [41]. The ENCODE project [42] has confirmed that this phenomenon is ubiquitous in higher genomes, wherein a given DNA sequence routinely encodes multiple overlapping messages, meaning that a single nucleotide can contribute to two or more genetic codes. Most recently, Itzkovitz et al. analyzed protein coding regions of 700 species, and showed that virtually all forms of life have extensive overlapping information in their genomes [43].
38. Sanford J (2008) Genetic Entropy and the Mystery of the Genome. FMS Publications, NY. Pages 131–142.
39. Trifonov EN (1989) Multiple codes of nucleotide sequences. Bull of Mathematical Biology 51:417–432.
40. Trifanov EN (1997) Genetic sequences as products of compression by inclusive superposition of many codes. Mol Biol 31:647–654.
41. Kapranov P, et al (2005) Examples of complex architecture of the human transcriptome revealed by RACE and high density tiling arrays. Genome Res 15:987–997.
42. Birney E, et al (2007) Encode Project Consortium: Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature 447:799–816.
43. Itzkovitz S, Hodis E, Sega E (2010) Overlapping codes within protein-coding sequences. Genome Res. 20:1582–1589.
http://www.worldscientific.com/doi/pdf/10.1142/9789814508728_0006
http://reasonandscience.heavenforum.org/t2276-two-of-the-most-convincing-arguments-for-intelligent-design
Hi Dr. Wile, The “universal code” is definitely not universal though it isn’t radically different either. It works and is read the same way in all organisms including viruses but some of the code is altered. I just want to clarify that I don’t believe anyone proposes that mtDNA had an alternative code when the organelles were originally formed. It is proposed, with a lot of observational evidence, that secondary codes evolved much later. If those engulfed bacteria had different codes then evolutionary biology would predict that all animals would have an alternative code since they began with one. As I wrote on FB and gave an example, although there are many alternative codes almost every one of them is in a very very small genome and most are in endosymbionts. In such small genomes it is not at all statistically improbable that some codons will go out of use completely and thus the tRNAs are available to be reassigned. This is even true in a few larger genomes that extremely high AT content. All of the alternative genetic codes reside is unusual genomes which is highly suggestive of special conditions that are necessary for their origin.
Just as an aside, I have alwas thought the genetic code would be the best way for God to give us a clear sign that all living things were created separately. There isn’t any obvious reason why one species could not have a very different genetic code. In fact biologists are able to change code in bacteria. If one species had 10 or 20 different codon assignment in a large genome that used those codons thousands of times this would very much point to separate creation. If human just had a different code than all other living things then we would be immune to HIV and all retroviruses. The alternative codes we do see in nature are not clear cut examples o separate creation because they show a pattern that suggests a very plausible origin via providential processes.
If people are proposing that the genetic codes changed over time, then as I mentioned in the article, that requires some serious explanation. It’s not enough to say, “well, these genomes are small, so it might be that some codons will go out of use.” You need to show exactly how this could happen. Even in a genome that has only 30-50 proteins, each protein is very long and uses the same amino acid multiple times. You need to show how it is possible for four codons to go completely out of use. Then, once they go completely out of use, how they can get reassigned in order to go from the “universal” code to the vertebrate mitochondrial code. Also, you have to show how this happened only at the base of the vertebrate tree.
I agree with you that different genetic codes are strong evidence for creation, and so far, several have been discovered. You try to claim, “The alternative codes we do see in nature are not clear cut examples o[f] separate creation because they show a pattern that suggests a very plausible origin via providential processes.” However, you haven’t come close to showing that there is a plausible evolutionary explanation. All you have done is special pleading based on small genomes.
You say “If human[s] just had a different code than all other living things then we would be immune to HIV and all retroviruses.” That’s true, but there is no reason to expect that in a creationist view. In fact, the Bible gives us the answer as to why God wouldn’t have created that way: the consequence of sin (Romans 8:20-22).
It’s probably why Dr. Craig Venter stunned Richard Dawkins in a panel they were both on a couple of years ago by denying common descent.
25 Genetic Codes
The following genetic codes are described here:
1. The Standard Code
2. The Vertebrate Mitochondrial Code
3. The Yeast Mitochondrial Code
4. The Mold, Protozoan, and Coelenterate Mitochondrial Code and the Mycoplasma/Spiroplasma Code
5. The Invertebrate Mitochondrial Code
6. The Ciliate, Dasycladacean and Hexamita Nuclear Code
9. The Echinoderm and Flatworm Mitochondrial Code
10. The Euplotid Nuclear Code
11. The Bacterial, Archaeal and Plant Plastid Code
12. The Alternative Yeast Nuclear Code
13. The Ascidian Mitochondrial Code
14. The Alternative Flatworm Mitochondrial Code
16. Chlorophycean Mitochondrial Code
21. Trematode Mitochondrial Code
22. Scenedesmus obliquus Mitochondrial Code
23. Thraustochytrium Mitochondrial Code
24. Pterobranchia Mitochondrial Code
25. Candidate Division SR1 and Gracilibacteria Code
I know that the numbers go up to 25, Chris, but some (7, 8, 15, 17, 18, 19, 20) are missing. I assume that’s because they haven’t been fully elucidated yet.
As an impressionable young student at the University of Rochester, I was taught quite definitively that there is only one code for DNA, and it is universal. Where such information?
I went to the University of Rochester, too,theospookden. I was told the same thing. I was also told that it was unequivocal proof of common ancestry.